 我有分寸
我有分寸
[译文]What is RCU, Fundamentally?
http://lwn.net/Articles/262464/
December 17, 2007
Paul E. McKenney, IBM Linux Technology Center
Jonathan Walpole, Portland State University Department of Computer Science
王旭 [gnawux(at)gmail.com] 翻译,2008年5月26日–6月1日
[编者注:本文是解释 read-copy-update 工作机制的三部曲的第一部。十分感谢 Paul McKenney 和 Jonathan Walpole 允许我们发表这些文章。剩余的两片将在随后几周中陆续发出。]
《RCU是什么?》第一部分
概述
Read-copy update (RCU) 是一种 2002 年 10 月被引入到内核当中的同步机制。通过允许在更新的同时读数据,RCU 提高了同步机制的可伸缩性(scalability)。相对于传统的在并发线程间不区分是读者还是写者的简单互斥性锁机制,或者是哪些允许并发读但同时不允许写的读写锁,RCU 支持同时一个更新线程和多个读线程的并发。RCU 通过保存对象的多个副本来保障读操作的连续性,并保证在预定的读方临界区没有完成之前不会释放这个对象。RCU定义并使用高效、可伸缩的机制来发布并读取对象的新版本,并延长旧版本们的寿命。这些机制将工作分发到了读和更新路径上,以保证读路径可以极快地运行。在某些场合(非抢占内核),RCU 的读方没有任何性能负担。
问题1:seqlock 不是也允许读线程和更新线程并发工作么?
这个问题可以归结到 “确切地说,什么是RCU?” 这个问题,或许还是 “RCU 可能是如何工作的?” (再或者,不太可能的情况下,问题会变为什么情况下 RCU 不太可能工作)。本文从几个基本的出发点来回答这些问题;之后还会分批地从使用的角度和 API 的角度来看这些问题。最后一篇连载还会给出一组参考文献。
RCU 由三个基本机制组成,第一个用于插入,第二个用于删除,而第三个则用于让读线程可以承受并发的插入或删除。这三个机制将在下面的三节中介绍,讲述如何将 RCU 转化为链表:
- 订阅发布机制 (用于插入)
- 等待已有的RCU读者完成 (用于删除)
- 维护多个最近更新的对象的版本 (为读者维护)
这三个章节之后还有上重点回顾与快速问题答案。
订阅发布机制
RCU的一个关键特性是它可以安全地扫描数据,即使数据正被同时改写也没问题。要提供这种并发插入的能力,RCU使用了一种订阅发布机制。举例说,考虑一 个被初始化为 NULL 的全局指针变量 gp 将要被修改为新分配并初始化的数据结构。下面这段代码(使用附加的合适的锁机制)可以用于这个目的:
1 struct foo {
2 int a;
3 int b;
4 int c;
5 };
6 struct foo *gp = NULL;
7
8 /* . . . */
9
10 p = kmalloc(sizeof(*p), GFP_KERNEL);
11 p->a = 1;
12 p->b = 2;
13 p->c = 3;
14 gp = p;
不幸的是,没有方法强制保证编译器和CPU能顺序执行最后四条语句。如果gp的赋值早于p的各个域的初始化的话,那么并发的读操作将访问到未初始化的变 量。内存屏障(barrier)可以用于保障操作的顺序,但内存屏障以难以使用而闻名。这样我们将他们封装到具有发布语义的 rcu_assign_pointer() 原语之中。最后的四条将成为这样:
1 p->a = 1;
2 p->b = 2;
3 p->c = 3;
4 rcu_assign_pointer(gp, p);
rcu_assign_pointer() 将会发布新的结构,强制编译器和CPU在给p的各个域赋值之后再把指针赋值给gp。然而,仅仅强制更新操作的顺序是不够的,读者也必须强制使用恰当的顺序。考虑下面的这段代码:
1 p = gp;
2 if (p != NULL) {
3 do_something_with(p->a, p->b, p->c);
4 }
尽管这段代码看起来不会受到顺序错乱的影响,不过十分不幸,DEC Alpha CPU 和投机性编译器优化可能会引发问题,不论你是否相信,这的确有可能会导致 p->a, p->b, p->c 的读取会在读取 p 之前!这种情况在投机性编译器优化的情况中最有可能会出现,编译器会揣测p的值,取出 p->a, p->b 和 p->c,之后取出 p 的真实值来检查拽侧的正确性。这种优化非常激进,或者说疯狂,不过在确实会在profile-driven优化时发生。
毫无疑问,我们需要在CPU和编译器上阻止这种情况的发生。rcu_dereference() 原语使用了必要的内存屏障指令和编译器指令来达到这一目的:
1 rcu_read_lock();
2 p = rcu_dereference(gp);
3 if (p != NULL) {
4 do_something_with(p->a, p->b, p->c);
5 }
6 rcu_read_unlock();
rcu_dereference() 原语可以被看作是订阅了指针指向的值,保证接下来的取值操作将会看到对应的发布操作(rcu_assign_pointer())发生之前被初始化的值。 rcu_read_lock() 和 rcu_read_unlock() 绝对是必须的:他们定义了 RCU 读方临界区的范围。他们的目的将在下一节 解释,不过,他们不会自旋或阻塞,也不阻止 list_add_rcu() 的并发执行。事实上,对于非抢占内核,它们不产生任何代码。
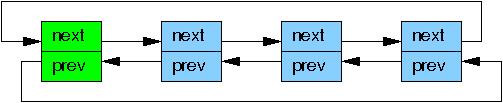
虽然 rcu_assign_pointer() 和 rcu_dereference() 在理论上可以用于构建任意 RCU 保护的数据结构,但实际上,使用高层构造常常更好。因此,rcu_assign_pointer() 和 rcu_dereference() 原语被嵌入到了 Linux 的链表维护 API 中的特殊 RCU 变量之中了。Linux 有两个双向链表的变种,循环链表 struct list_head 和线性链表 struct hlist_head/struct hlist_node。前者的结构如下图所示,绿色的方块表示表头,蓝色的是链表中的元素。
将上面的指针发布例子放到链表的场景中来就是这样:
1 struct foo {
2 struct list_head list;
3 int a;
4 int b;
5 int c;
6 };
7 LIST_HEAD(head);
8
9 /* . . . */
10
11 p = kmalloc(sizeof(*p), GFP_KERNEL);
12 p->a = 1;
13 p->b = 2;
14 p->c = 3;
15 list_add_rcu(&p->list, &head);
第15行被使用某种同步机制保护住了,通常是某种所,以组织多个 list_add() 实例并发执行。然而,这些同步不能组织同时发生的RCU读者。订阅一个 RCU 保护的链表非常直接:
1 rcu_read_lock();
2 list_for_each_entry_rcu(p, head, list) {
3 do_something_with(p->a, p->b, p->c);
4 }
5 rcu_read_unlock();
list_add_rcu() 原语发布一个节点到制定的链表中去,保证对应的 list_for_each_entry_rcu() 调用都正确的订阅到同一个节点上。
问题2:如果在 list_for_each_entry_rcu() 运行时,刚好进行了一次 list_add_rcu(),如何防止 segfault 的发生呢?
Linux 中的另一个双向链表,hlist,是一个线性表,也就是说,它的头部仅需要一个指针,而不是向循环链表一样需要两个指针。这样,使用 hlist 作为大型哈希表的 hash-bucket 数组的容器将仅消耗一半的内存空间。

将一个新元素添加到一个 RCU 保护的 hlist 里面与添加到循环链表里非常类似:
1 struct foo {
2 struct hlist_node *list;
3 int a;
4 int b;
5 int c;
6 };
7 HLIST_HEAD(head);
8
9 /* . . . */
10
11 p = kmalloc(sizeof(*p), GFP_KERNEL);
12 p->a = 1;
13 p->b = 2;
14 p->c = 3;
15 hlist_add_head_rcu(&p->list, &head);
和上面一样,第15行一定使用了锁或其他某种同步机制。
订阅一个 RCU 保护的 hlist 也和循环链表非常接近。
1 rcu_read_lock();
2 hlist_for_each_entry_rcu(p, q, head, list) {
3 do_something_with(p->a, p->b, p->c);
4 }
5 rcu_read_unlock();
问题3:为什么我们需要传递两个指针给 hlist_for_each_entry_rcu(), list_for_each_entry_rcu() 可是只需要一个指针的啊?
RCU 发布与订阅原语在如下表中列出,同时给出了 “取消发布”或是撤回的原语
类别
发布
撤销
订阅
类别
发布
撤销
订阅
指针
rcu_assign_pointer()
rcu_assign_pointer(…, NULL)
rcu_dereference()
循环链表
list_add_rcu()
list_add_tail_rcu()
list_replace_rcu()
list_del_rcu()
list_for_each_entry_rcu()
双向链表
hlist_add_after_rcu()
hlist_add_before_rcu()
hlist_add_head_rcu()
hlist_replace_rcu()
hlist_del_rcu()
hlist_for_each_entry_rcu()
注意,list_replace_rcu(), list_del_rcu(), hlist_replace_rcu(), 以及 hlist_del_rcu() 增加了一些复杂度。什么时候释放被替换或删除掉的数据元素才是安全的呢?具体地说,我们怎么能知道所有的读者都释放了他们手中对数据元素的引用呢?
这些问题将在下面的章节中得到回答。
等待已经存在的RCU读者完成
RCU的最基本的功能就是等待一些事情的完成。当然,还有很多其他方法也是用于等待事情完成的,包括引用计数、读写锁、事件等。RCU最大的好处在于它可以等待所有(比如说)两万件不同点事情,而无需显式地跟踪它们中的每一个,也不需要担心性能的下降、可伸缩性限制、复杂度死锁场景,以及内存泄露等所有这些显式跟踪手法所固有的问题。
RCU 中,被等待的东西被叫做“RCU读方临界区”。一个RCU读方临界区始于 rcu_read_lock() 原语,止于 rcu_read_unlock() 原语。RCU 读方临界区可以嵌套,也可以放入很多代码,只要这些代码显式阻塞或睡眠即可(有一种称为“SRCU”的特殊RCU允许在它的读方临界区中睡眠)。只要你遵守这些约定,你就可以使用RCU来等待任何期望的代码段的完成。
正如其他地方对经典RCU和实时RCU的描述,RCU 通过间接确定这些其他事情的完成时间来达到这一目的。
具体地说,如下图所示,RCU是一种等待已经存在的RCU读方临界区结束的方法,包括这些临界区中执行的内存操作。
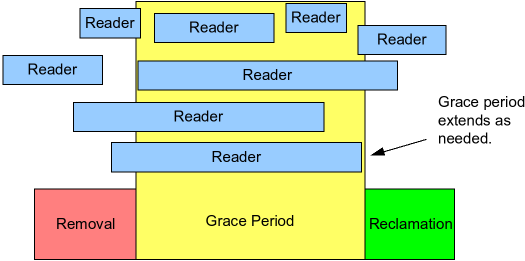
注意,开始于一个给定宽限期开始之后的RCU读方临界区能够、并可以延续到该宽限期结束之后。
下面的伪码展示了使用RCU等待读者的基本算法形式:
- 进行改动,比如,替换链表中的一个元素。
- 等待所有已经存在的RCU读方临界区完成(比如,使用synchronize_rcu()原语)。关键点是接下来的RCU读方临界区将无法得到新近删除的元素的引用了。
- 清理,比如,释放上述所有被替换的元素。
下面的代码段是从前一节修改而得的,用于说明这一过程,这里面的域a是这个搜索的键值。
1 struct foo {
2 struct list_head list;
3 int a;
4 int b;
5 int c;
6 };
7 LIST_HEAD(head);
8
9 /* . . . */
10
11 p = search(head, key);
12 if (p == NULL) {
13 /* Take appropriate action, unlock, and return. */
14 }
15 q = kmalloc(sizeof(*p), GFP_KERNEL);
16 *q = *p;
17 q->b = 2;
18 q->c = 3;
19 list_replace_rcu(&p->list, &q->list);
20 synchronize_rcu();
21 kfree(p);
第19、20 和 21 行实现了上面所说的三个步骤。第 16-19行展现了 RCU 的名字(读-复制-更新):在允许进行并发读操作的同时,第16行进行了复制,而第17-19行进行了更新。
乍一看会觉得 synchronize_rcu() 原语显得比较神秘。毕竟它必须等所有读方临界区完成,而且,正如我们前面看到的,用于限制RCU读方临界区的rcu_read_lock() 和 rcu_read_unlock() 原语在非抢占内核中甚至什么代码都不会生成。
这里有一个小伎俩,经典RCU通过 rcu_read_lock() 和 rcu_read_unlock() 界定的读方临界区是不允许阻塞和休眠的。因此,当一个给定的CPU要进行上下文切换的时候,我们可以确定任何已有的RCU读方临界区都已经完成了。也就是说,只要每个CPU都至少进行了一次上下文切换,那么所有先前的 RCU 读方临界区也就保证都完成了,即 synchronize_rcu() 可以安全返回了。
因此,经典RCU的 synchronize_rcu() 从概念上说可以被简化成这样:
1 for_each_online_cpu(cpu)
2 run_on(cpu);
这里,run_on() 将当前线程切换到指定 CPU,来强制该 CPU 进行上下文切换。而 for_each_online_cpu() 循环强制对每个 CPU 进行一次上下文切换。虽然这个简单的方法可以在一个不支持抢占的内核上工作,换句话说,对 non-CONFIG_PREEMPT 和 CONFIG_PREEMPT,但对 CONFIG_PREEMPT_RT 实时 (-rt) 内核无效。因此,实时RCU使用了一个(松散地)基于引用计数的方法。
当然,在真实内核中的实现要复杂得多了,因为它需要管理终端,NMI,CPU热插拔和其他实际内核中的可能有的风险,而且还要维护良好的性能和可伸缩性。RCU的实时实现还必须拥有良好的实时响应能力,这就使得(像上面两行那样)直接禁止抢占变得不可能了。
虽然我们了解到了 synchronize_rcu() 的简单实现原理,不过还有很多其它问题呢。比如,RCU读者们在读一个正在被并发地更新的链表的时候究竟读到了什么呢?这个问题将在下一节讲到。
维护多个版本的近期更新的对象
本节将展示 RCU 如何为多个不需要同步的读者维护不同版本的链表。我们使用两个例子来展示一个可能被给定的读者引用的元素必须在该读者处于读方临界区的整个过程中保持完好无损。第一个例子展示了链表元素的删除,而第二个例子则展示了元素的替换。
例1:在删除时维护多个版本
要开始这个“删除”的例子,我们先把上节这个例子的 11-21行改成如下的形式:
1 p = search(head, key);
2 if (p != NULL) {
3 list_del_rcu(&p->list);
4 synchronize_rcu();
5 kfree(p);
6 }
这个链表以及指针p的最初情况是这样的:
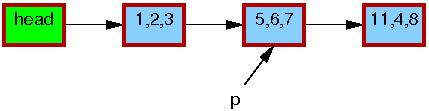
表中每个元素的三元组分别代表域a, b, c。红色的便捷表明读者可以获取它们的指针,而且因为读操作和更新操作不是直接同步的,读者可以在这个删除的过程中同时发生。这里我们为了清晰没有画出双向链表的反向指针。
在第三行的 list_del_rcu() 完成的时候,5,6,7 这个元素已经被从链表中删除了(如下图)。由于读者并不直接和更新操作同步,读者可能同时正在扫描这个链表。由于访问时间不同,这些并发读者可能看到、也可能没看到新近删除的元素。不过,那些在获取指针之后延迟了读操作的读者(比如因为中断、ECC内存错误,或在 CONFIG_PREEMPT_RT内核中因为抢占而延迟了的)可能仍然会在删除之后的一段时间内看到那个老的链表的版本。下图中 5,6,7 元素的边框仍然是红色的,这意味着仍然有读者可能会引用它。
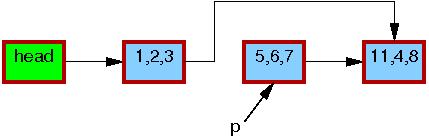
这里注意,在退出读方临界区之后,读者们就不能再持有 5,6,7 这个元素的引用了。所以,一旦第4行的 synchronize_rcu() 完成了,所有已有读者也就保证都完成了,这样就没有读者会访问这个元素了,下图中,这个元素的边框也变黑了。我们的链表也回到了一个单一的版本了。
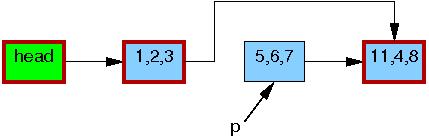
这之后,5,6,7 这个元素就可以被安全的释放了:
这里,我们完成了删除 5,6,7 这个元素的操作,下一小节将介绍替换操作。
例2:在替换的过程中维护数据的多个不同版本
在开始替换的例子钱,我们再修改一下前面例子的最后几行:
1 q = kmalloc(sizeof(*p), GFP_KERNEL);
2 *q = *p;
3 q->b = 2;
4 q->c = 3;
5 list_replace_rcu(&p->list, &q->list);
6 synchronize_rcu();
7 kfree(p);
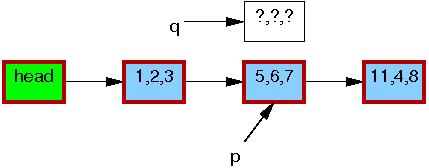
这个链表的初始状态和指针p和删除的那个例子是完全一样的:
和之前一样,每个元素里面的三元组分别代表域 a, b 和 c。红色的边框代表了读者可能会持有这个元素的引用,因为读者和更新者没有直接的同步,读者可能会和整个替换过程并发进行。再次说明,这里我们为了清晰,再次省略了反向指针。
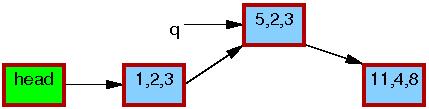
第一行的 kmalloc() 生成了一个替换元素,如下:
第二行把旧的元素的内容拷贝给新的元素:
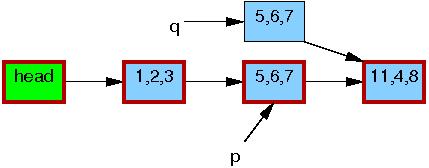
第三行,将 q->b 更新为2:
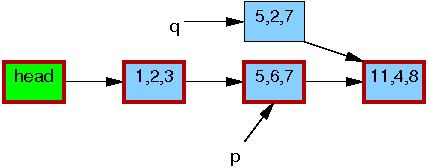
第四行,将 q->c 更新为3:
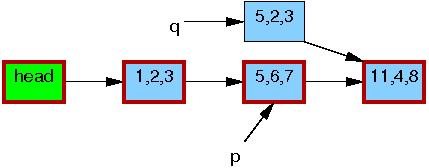
现在,第5行进行替换操作,这里,新元素最终对读者可见了。到了这里,如下所示,我们有了这个链表的两个版本。先前已经存在的读者可以看到 5,6,7 元素,而新读者将看到 5,2,3 元素。不过,任何读者都被保证可以看到一个完整的链表。
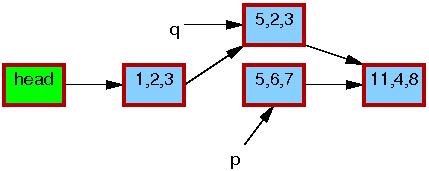
第6行的 synchronize_rcu() 返回后,宽限期将完成,所有在 list_replace_rcu() 之前开始的读者都将完成。具体地说,任何可能持有 5,6,7 的读者都已经退出了他们的读方临界区,这就保证他们不再持有一个引用。因而也在没有任何读者持有老元素的引用了,途中,5,6,7 元素的边框也就变黑了。对于读者来说,目前又只有一个单一的链表版本了,只是新的元素已经替代了旧元素的位置。
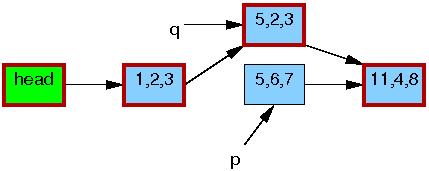
第七行的 kfree() 完成后,链表旧成为了如下的样子:
尽管 RCU 是以替换而命名的,但内核中的大多数使用都是前面小节 中的简单删除的情况。
讨论
这个例子假设在更新操作的过程中保存着一个互斥量,也就是说,这个链表在一个给定时间最多有两种版本。
问题4:如何修改删除的例子,来允许超过两个版本的链表可以同时存在?
问题5:在某一时刻,RCU最多可以有多少个链表的版本?
这组例子显示了RCU使用多个版本来保障在存在并发读者的情况下的安全更改数据。当然,一些算法是无法很好地支持多个版本的。有一个参考文献 介绍了如何对这些算法进行改造以使用RCU,不过,这超出了本文的讨论范围了。
小结
本文介绍了基于RCU的算法的三个基本部分:
- 对与添加新数据的发布-订阅机制
- 等待已有RCU读者完成,以及
- 维护多个版本以便在不顺坏或严重延迟RCU读者的情况下,允许更改。
问题6:如果 rcu_read_lock() 与 rcu_read_unlock() 之间没有自旋锁或阻塞,RCU更新者会如何影响RCU读者的性能?
这三个RCU的组成部分允许数据在并发读者访问的同时更新数据,并可以以多种方式实现基于RCU的算法,一些算法将会在接下来的“What is RCU, Really?”系列中继续介绍。
致谢
我 们十分感激本文草稿的审阅者,他们极大地提高了本文的价值,这些审阅者是 Andy Whitcroft, Gautham Shenoy, 和 Mike Fulton。同时,我们要感谢 Relativistic Programming 项目的成员和 PNW TEC 的成员,他们带来乐很多有价值的讨论。我们还要感谢 Dan Frye 的支持。最后,本文基于 NSF CNS-0719851 资助项目的工作。
本文仅代表作者的个人观点,并不反映 IBM 或波特兰州立大学的观点。
Linux 是 Linus Torvalds 的注册商标。
其他涉及到的公司、产品和服务的名称是各自的商标或服务标志。
问题解答
问题1:seqlock 不是也允许读线程和更新线程并发工作么?
答:是或不是。虽然 seqlock 的读者可以在 seqlock 写的同时并发访问,不过一旦写操作发生,read_seqretry() 原语都会强制要求读者重试。这意味着任何与 seqlock 更新者并发发生的 seqlock 读者所做的工作都将被放弃并重做。所以,seqlock 读者可以与更新者同时运行,但不能真的在这种情况下做什么工作。
与此相反,RCU 读者可以在存在并发 RCU 更新者的同时完成有效地工作。
问题2:如果在 list_for_each_entry_rcu() 运行时,刚好进行了一次 list_add_rcu(),如何防止 segfault 的发生呢?
答:在所有运行着的 Linux 系统中,从指针读取或写入指针都是原子操作,也就是说,如果一个存储到指针和一个从指针读取操作是同时发生的,那么,读取要么读回初始值,要么读回存入值,而不会返回两者的混合体。另外,list_for_each_entry_rcu() 总会前向遍历链表,而从不反向遍历。因而,list_for_each_entry_rcu() 要么看到 list_add_rcu() 加入后的元素,要么看不到,不论如何,都会看到一个正确的链表。
问题3:为什么我们需要传递两个指针给 hlist_for_each_entry_rcu(), list_for_each_entry_rcu() 可是只需要一个指针的啊?
答:因为一个 hlist 必须检查 NULL 而不是检查是不是回到头部了。(尝试编一个单指针的 hlist_for_each_entry_rcu()。如果你能得到一个不错的答案,那当然是非常好的事情啦!)
问题4:如何修改删除的例子,来允许超过两个版本的链表可以同时存在?
a答:一个方法可以通过如下代码达到:
spin_lock(&mylock);
p = search(head, key);
if (p == NULL)
spin_unlock(&mylock);
else {
list_del_rcu(&p->list);
spin_unlock(&mylock);
synchronize_rcu();
kfree(p);
}
注意,这意味着 synchronize_rcu() 可以等待多个并发的删除操作。
问题5:在某一时刻,RCU最多可以有多少个链表的版本?
答:这依赖于同步时如何设计的。如果用一个信号量来保护宽限期内的变更操作,那么最多有新旧两个版本。然而,如果仅仅搜索、更新,并用锁来保护 list_replace_rcu(),那么可以有任意数量的活动版本,只受到内存和宽限期内可以完成多少个更新操作的限制。不过,要注意,那些如此频繁更新的数据结构不是实施RCU的好场所。这只是说,RCU 可以在必要时应付高更新速率。
问题6:如果 rcu_read_lock() 与 rcu_read_unlock() 之间没有自旋锁或阻塞,RCU更新者会怎样影响RCU读者的性能?
答:某个CPU上运行的更新者会导致所在CPU上的 cache line 失效,并强制其他运行 RCU读者的 CPU 也丢弃 cache line,从而导致 cache 重新映射造成的昂贵代价。(你能设计一个算法来改变一个数据结构而不导致并发读者的昂贵的 cache 丢失么?对接下来的其他读者呢?)